Если действительно разобраться и копнуть немного глубже, то Google, а потом и Дуг сделали инструмент(и далеко не идеальный, как призналось Google, спустя несколько лет), для решения конкретного класса задач — построение поискового индекса.
Инструмент получился неплохим, но есть одна проблема, в прочем, обо всем по порядку.
В начале 2012 года начался агрессивный тренд — "эпоха big data".
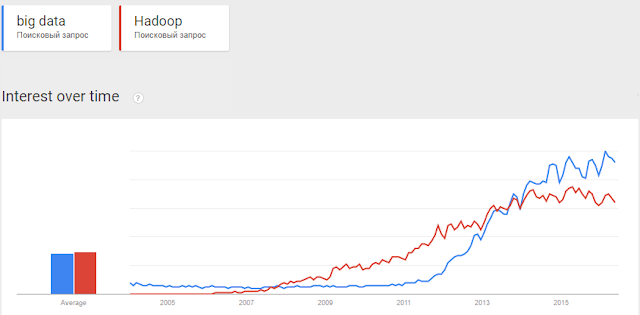
Именно с этого момента начали появляться бесполезные статьи и даже книги в стиле "Как стать big data company" или "Большие данные решают все". Ни одна из конференций больше не обходилась без рассуждений о том, "с какого терабайта начиналась big data" и повторяющихся историй о том, как "одна компания была почти на грани дефолта, но таки перешла на большие данные и она просто порвала рынок". Вся это пустая болтовня подкармливалась грамотным маркетингом от компаний, которые продавали поддержку на все это — спонсировались хакатоны, семинары и много-много всего.
В конечном итоге у большого количества людей сложилась конкретная картина мира, в которой традиционные решения — это медленно, это дорого, да и как минимум, это больше не модно.
Прошло уже много лет, но до сих пор я вижу обсуждения и статьи с заголовками "Map Reduce: first steps" или "Big Data: What Does it Really Mean?" на профессиональных ресурсах.
Hadoop как средство для индексирования
Что же все-таки такое Hadoop? В общих словах это файловая система HDFS и набор инструментов для обработки данных.
Все это размазано по кластеру из "дешевого железа" и по мнению маркетологов должно в мановение ока завалить вас деньгами, которые будут приносить "большие данные".
Крупные интернет-компании, например Yahoo, в свое время, оценили Hadoop, как средство обработки больших объемов информации. Используя MapReduce, они могли строить поисковые индексы на кластерах из тысяч машин.
Надо сказать, тогда это было действительно прорывом — Open Source продукт умеет решать задачи такого класса и все это бесплатно. Yahoo сделало ставку на то, что возможно в будущем им бы не пришлось выращивать специалистов, а набирать со стороны уже готовых.
Но я не знаю когда первая обезьяна спустилась с дерева, взяла палку и начала использовать MapReduce для аналитики данных, но факт остается фактом, MapReduce начал реально появляться там, где это совершенно не нужно.

Демонстрация Hadoop пользователям
https://habrahabr.ru/post/303802/